1
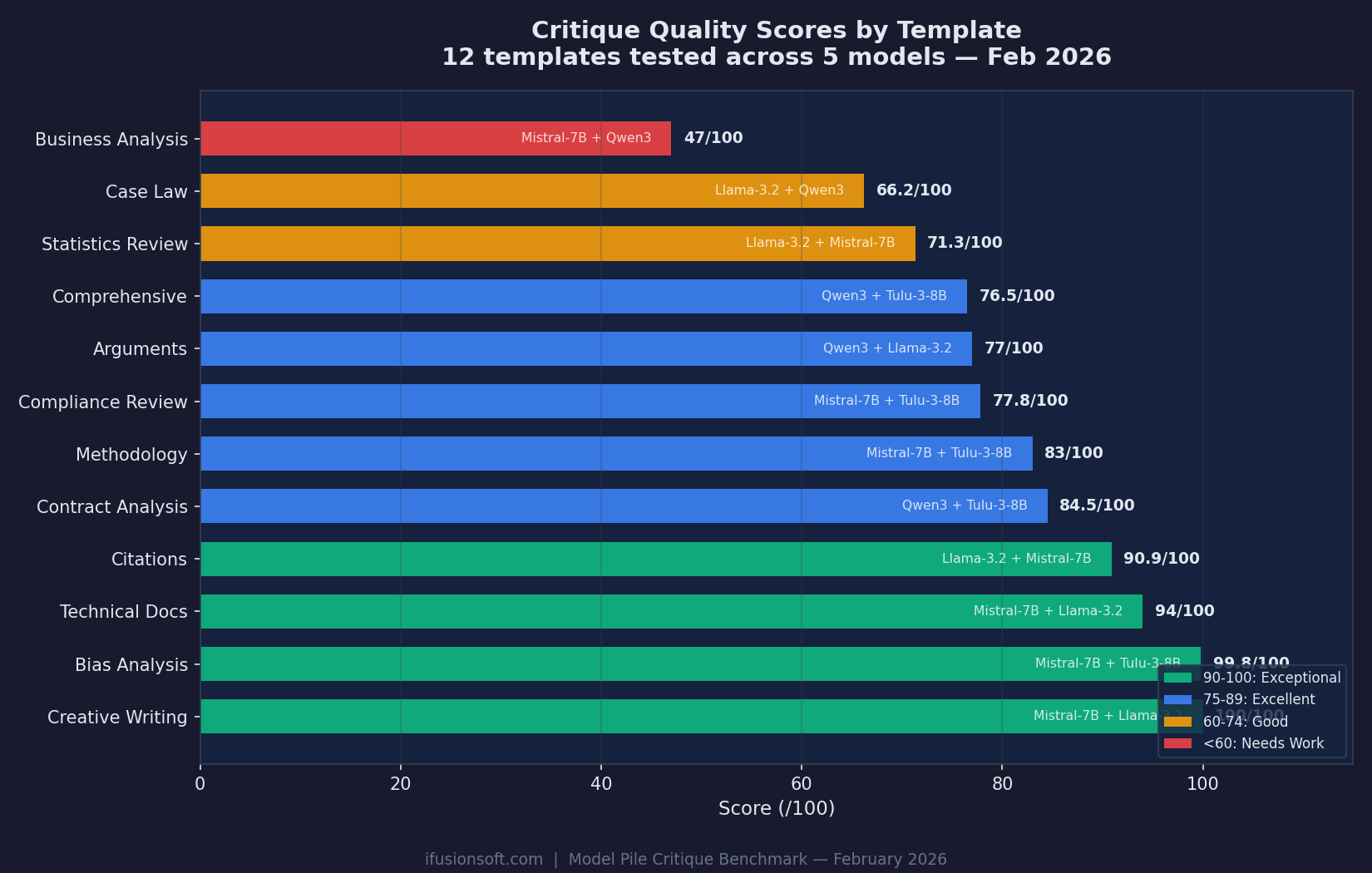
Critique Scores: 47 to 100 Across 12 Templates
Each template reveals different model strengths. Creative Writing and Bias Analysis hit near-perfect scores. Business Analysis remains the hardest challenge.
We rigorously test every model before you use it. Select a benchmark report to explore the results.
Each template reveals different model strengths. Creative Writing and Bias Analysis hit near-perfect scores. Business Analysis remains the hardest challenge.
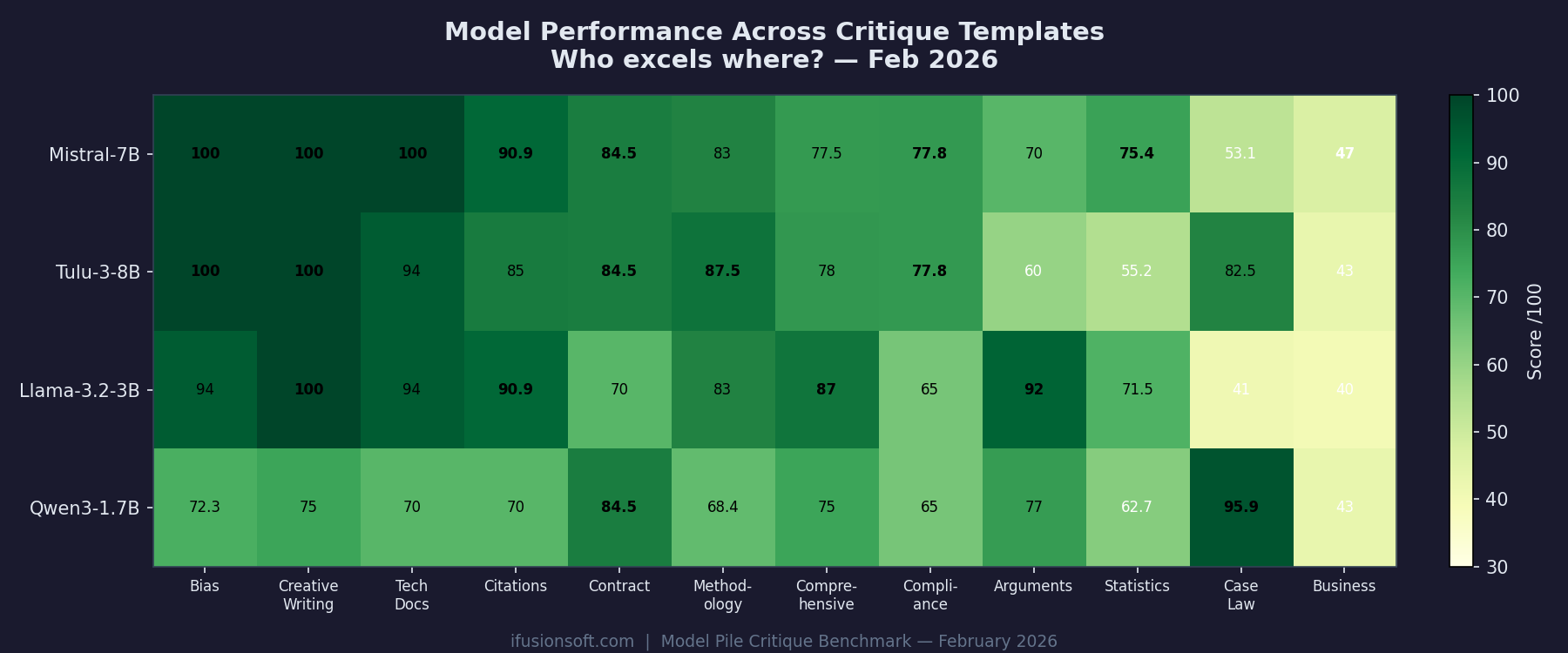
Mistral-7B hits perfect 100 on Bias, Creative Writing, and Tech Docs. Qwen3-1.7B dominates Case Law (95.9). No model leads everywhere.
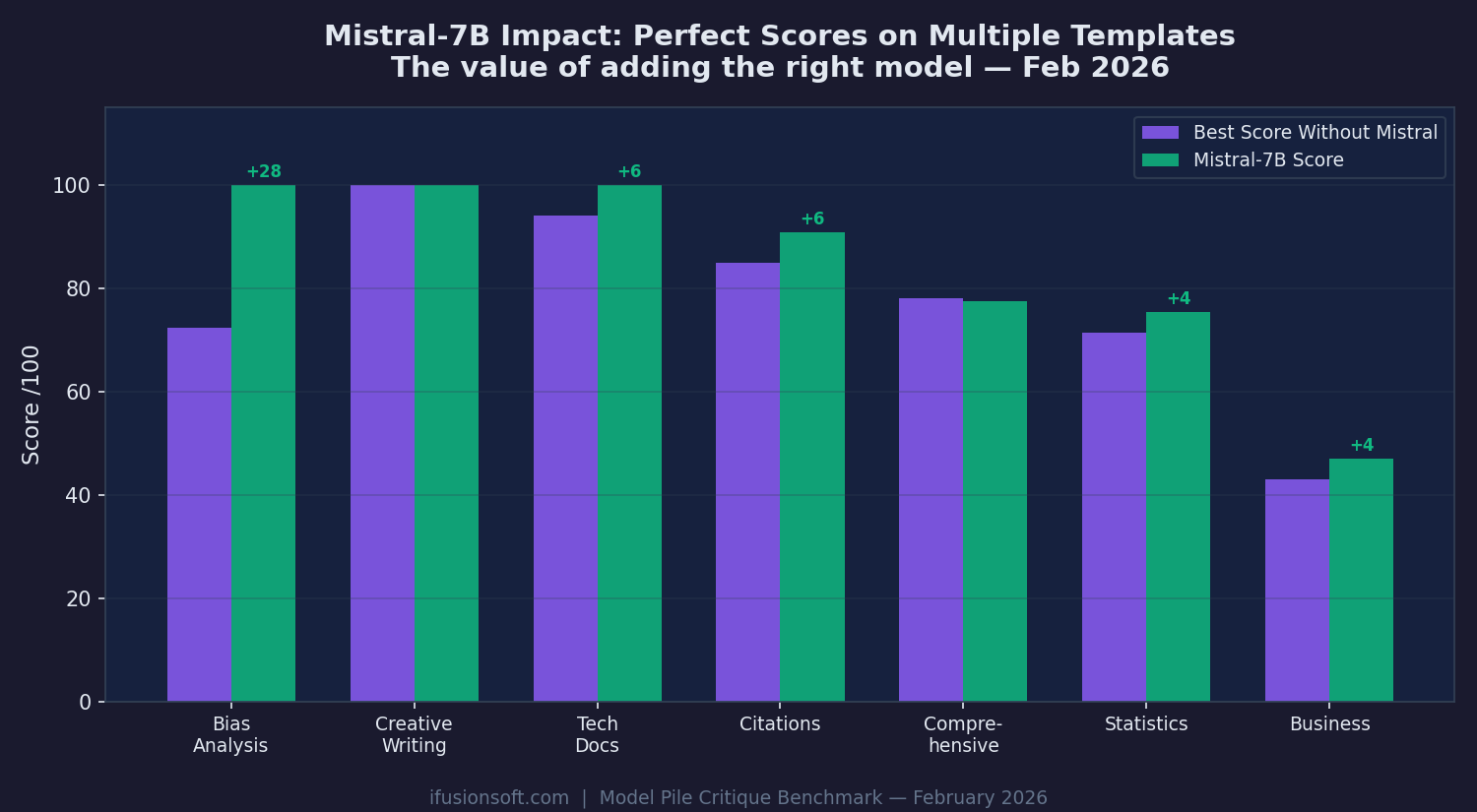
When we added Mistral-7B-Instruct, Bias Analysis jumped +28 points to a perfect 100. Tech Docs gained +6. Every template improved.
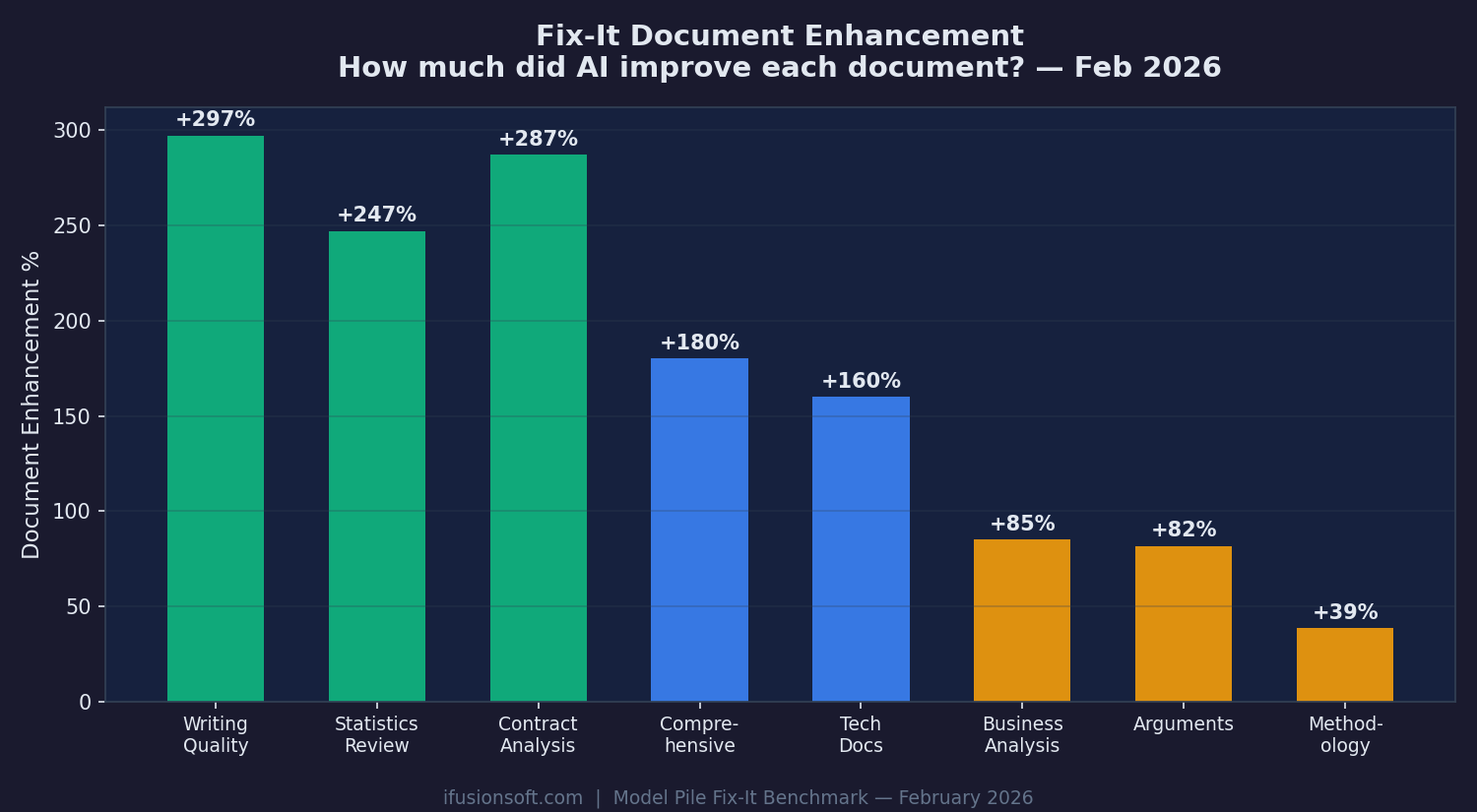
After critique analysis identifies issues, the Fix-It process rewrites documents. Writing Quality documents grew +297%. Contract Analysis grew +287%.
Pro vs Con and Contract Terms debates scored highest (0.78-0.79). Philosophical and Scientific debates are hardest. 100% Fix-It success across all templates.

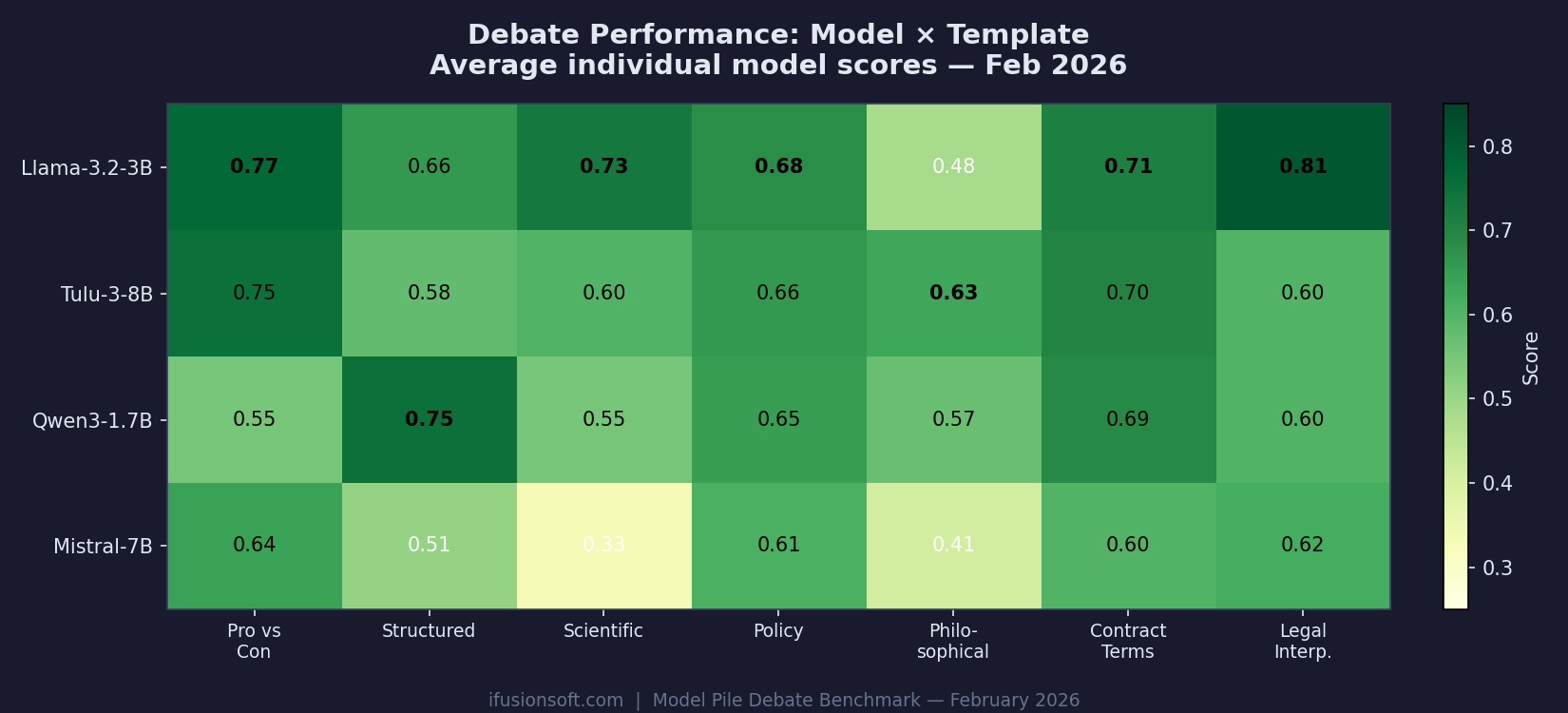
Llama-3.2-3B leads Legal Interpretation (0.81) and Scientific debate (0.73). Qwen3 dominates Structured debate (0.75). Mistral-7B struggles with Scientific (0.33) and Philosophical (0.41).
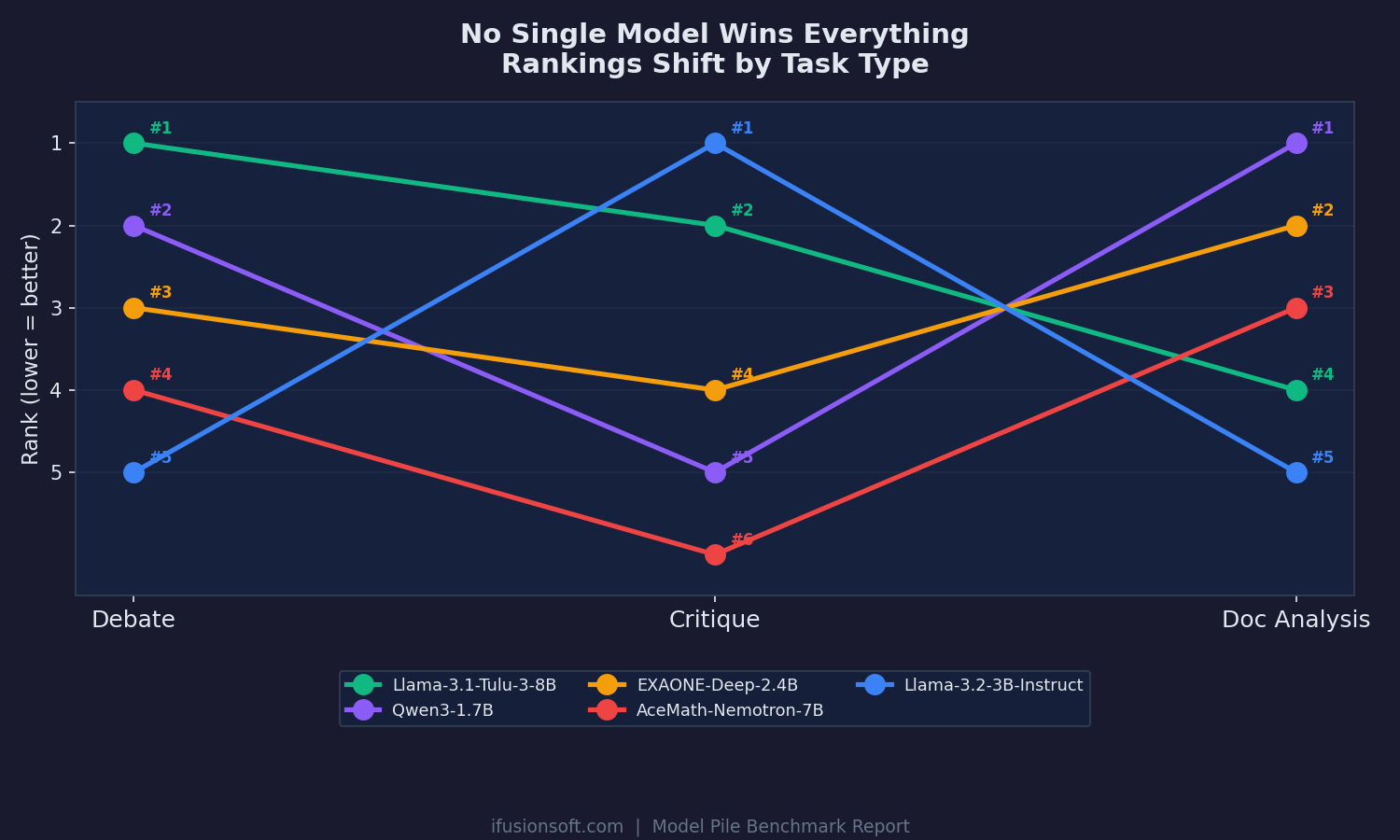
Rankings shift dramatically across task types. The debate champion drops to #4 in document analysis. The critique leader ranks #5 in debate.
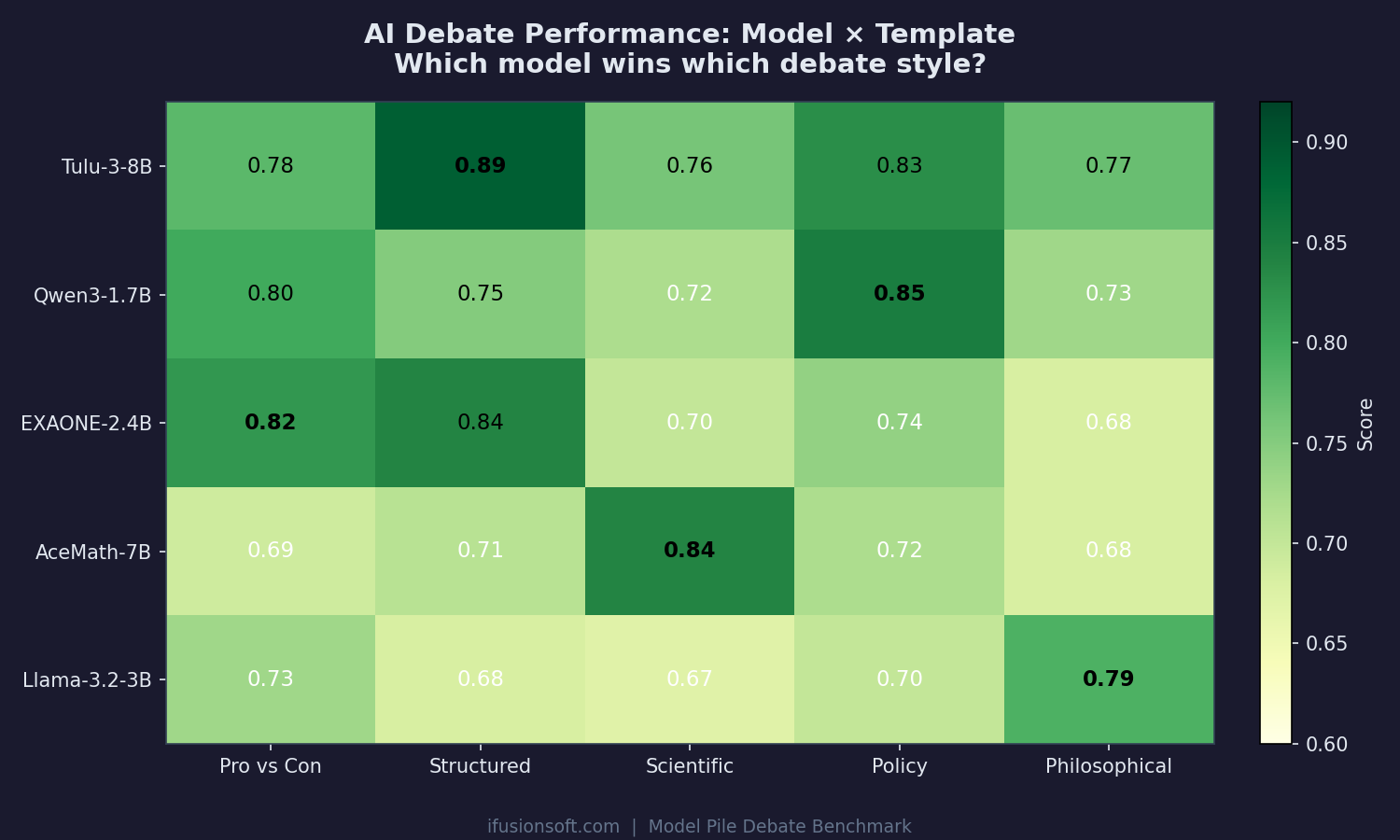
Each model has a debate style where it excels. Tulu-3 dominates structured debates (0.89), Qwen3 owns policy (0.85), AceMath leads scientific (0.84).
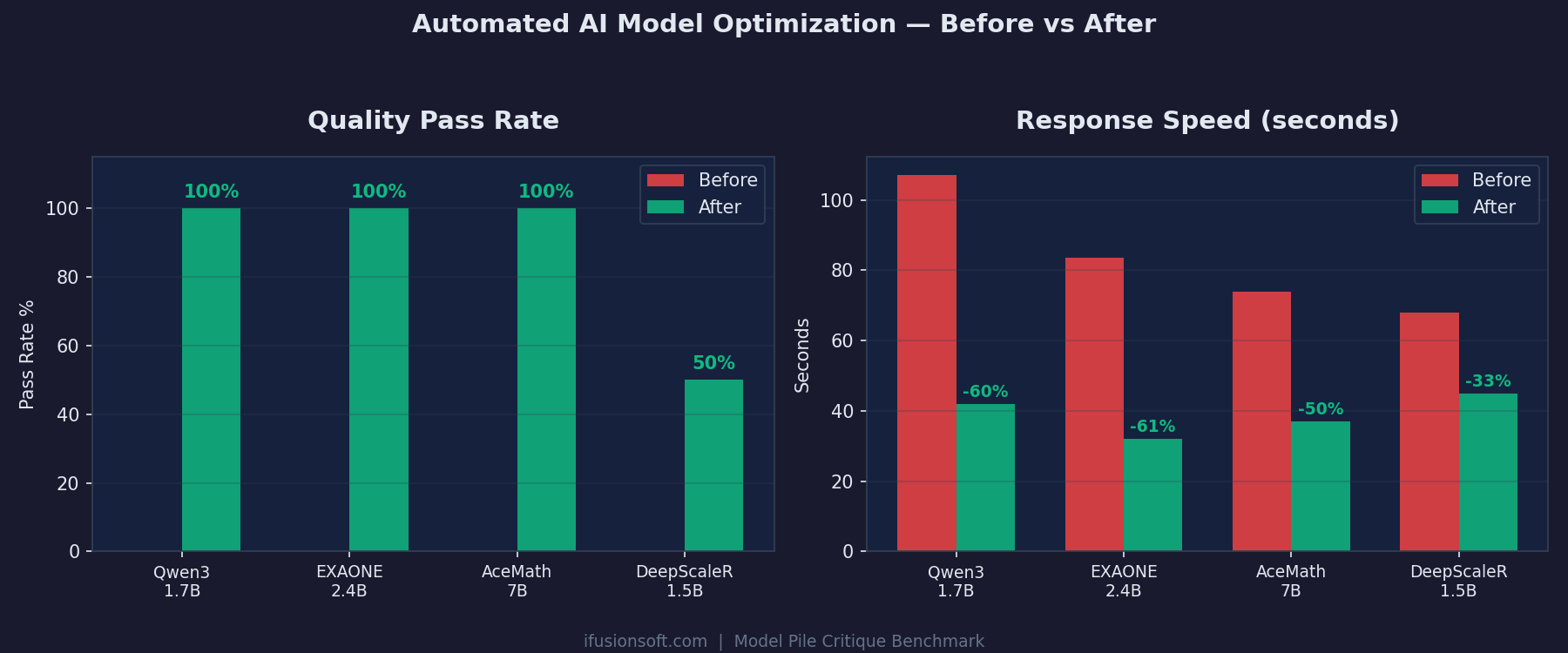
Four models initially failed critique quality checks. After automated parameter tuning, three reached 100% pass rate with up to 61% speed improvement.
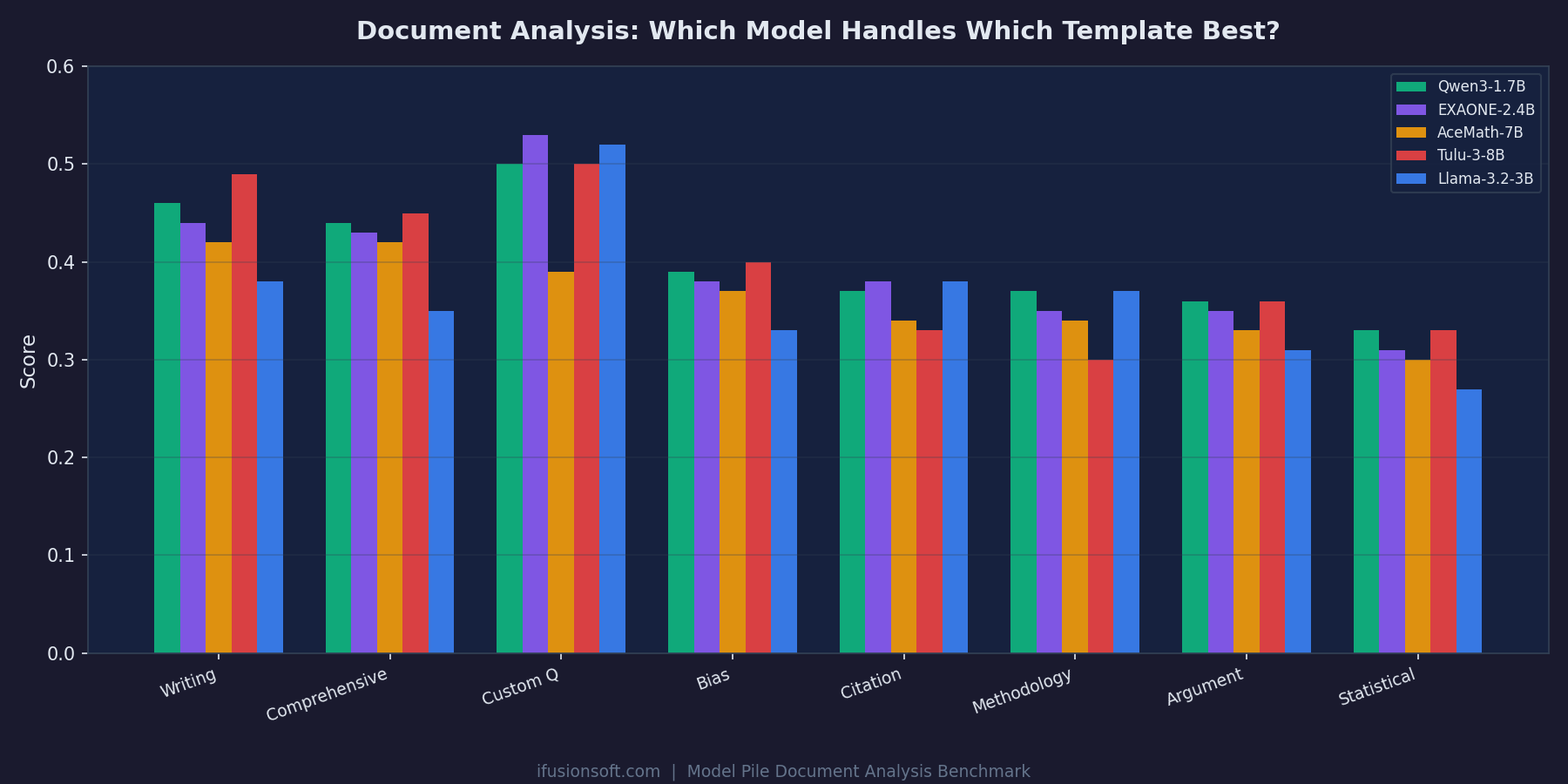
From Writing Quality to Statistical Review, each template reveals different strengths. The top 3 models are separated by just 0.018 points.
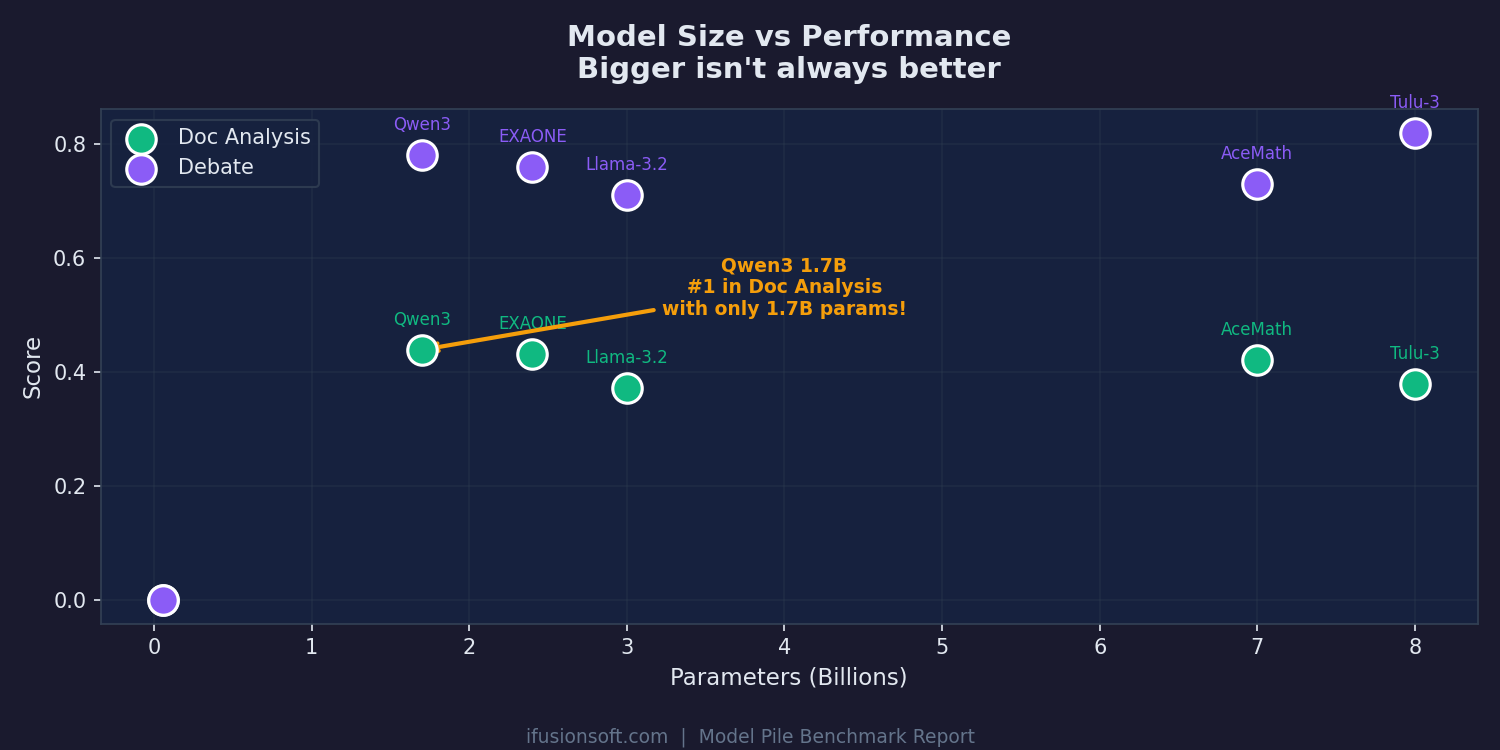
Qwen3 with only 1.7B parameters beats 7B and 8B models in document analysis. Performance depends on task fit, not parameter count.
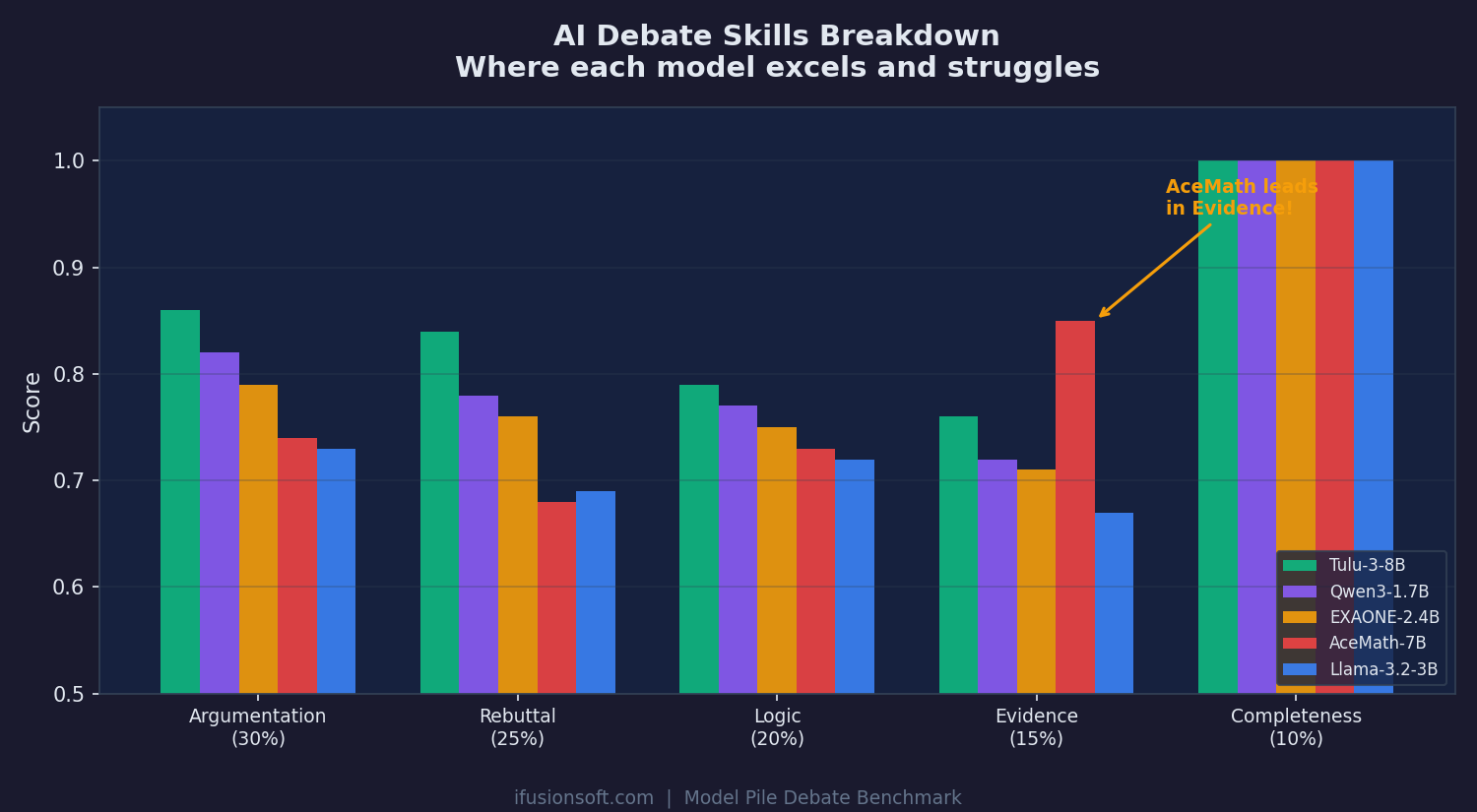
Scored across Argumentation (30%), Rebuttal (25%), Logic (20%), Evidence (15%), and Completeness (10%). AceMath — a math model — leads in evidence usage.
These benchmarks drive how Model Pile selects and combines models for every query you run.
Try Model Pile